
OpenAIを使ってNotionのページを検索する
課題
Notionはドキュメント、ミーティングの議事録、チケットなどを非常に管理しやすいツールですが、ドキュメントが増える一方で整理を怠る傾向が一般的です。そのため、必要な情報を抜き出すための資料検索が容易ではありません。Notionの検索機能はページのタイトルやタグなどのメタデータを検索できますが、ページの内容を直接検索できません。ページの内容を検索するには、ページを開いてからブラウザの検索機能を利用する必要があります。これは非常に面倒です。
ChatGPTのように、質問をするとAIがドキュメントを検索して回答を提供してくれる機能は、解決策の1つとして有用ではないでしょうか。私もそれを実装してみました。
TL;DR
https://github.com/thundermiracle/next-notion-search-openaiをcloneして、.env.exampleを.envにリネームし、手順通り中の環境変数を設定すれば検索サービスを簡単に立ち上げられます。
前提条件
supabaseコミュニティのこのレポジトリをベースにして作りました。https://github.com/supabase-community/nextjs-openai-doc-searchもちろん、pgvectorをサポートしているサービスなら、どこでも問題ありません。
- ベクトル検索の基本知識
supabaseのこのブログを読めば十分理解できるでしょう。https://supabase.com/blog/openai-embeddings-postgres-vector - supabaseの基本知識
検索用のベクトルを作成するフロー
- NotionのページをNotionAPIで取得する
- 取得したページをMarkdownの文字列へ変換
- Markdownの文字列をASTへ変換して、セクションごとで分割する
- OpenAIのEmbeddingsモデル(text-embedding-ada-002)を使って、セクションごとのベクトルを生成し、PostgreSQLのpgvector(supabase)に保存する
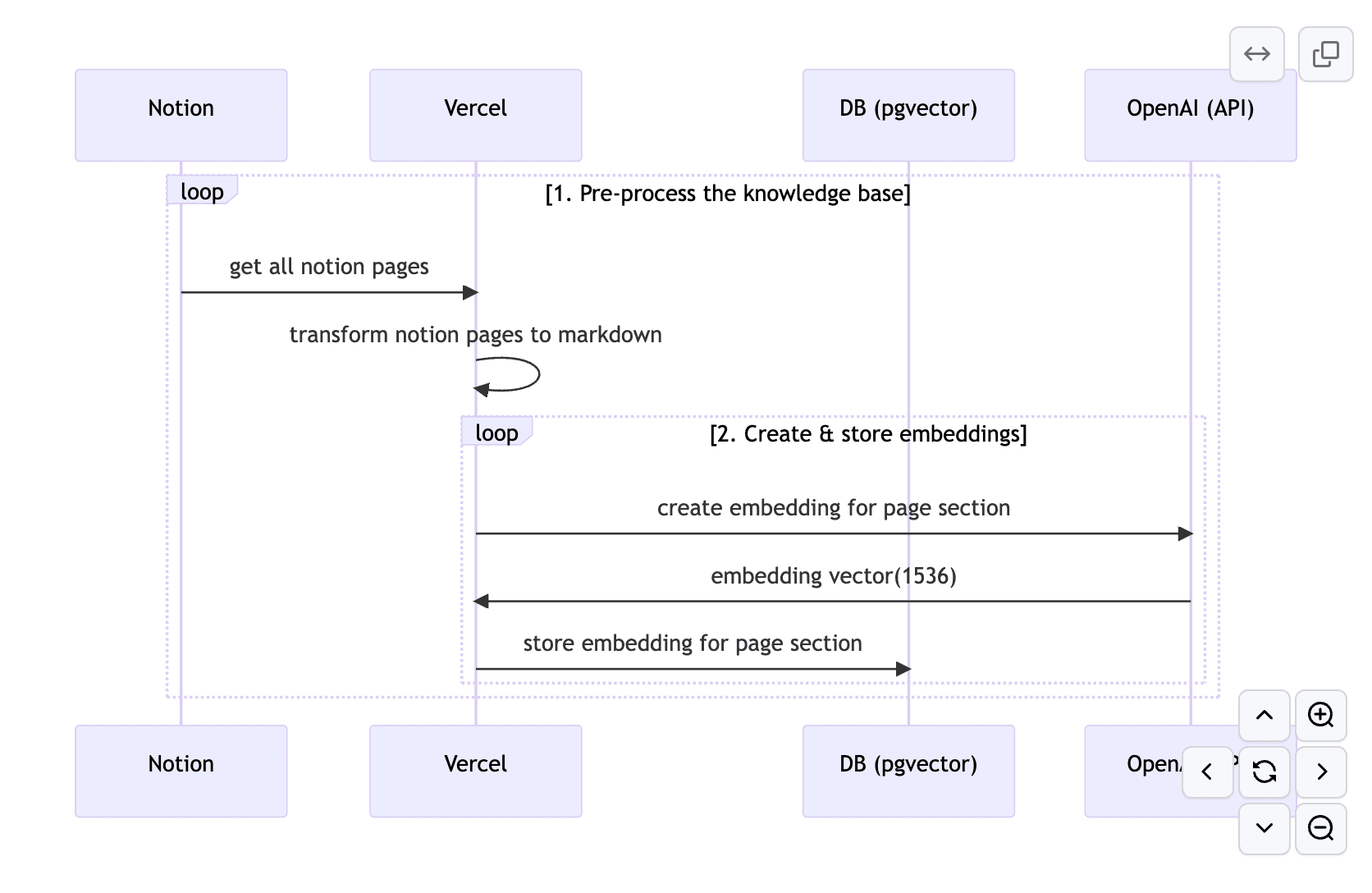
NotionのページをNotionAPIで取得する
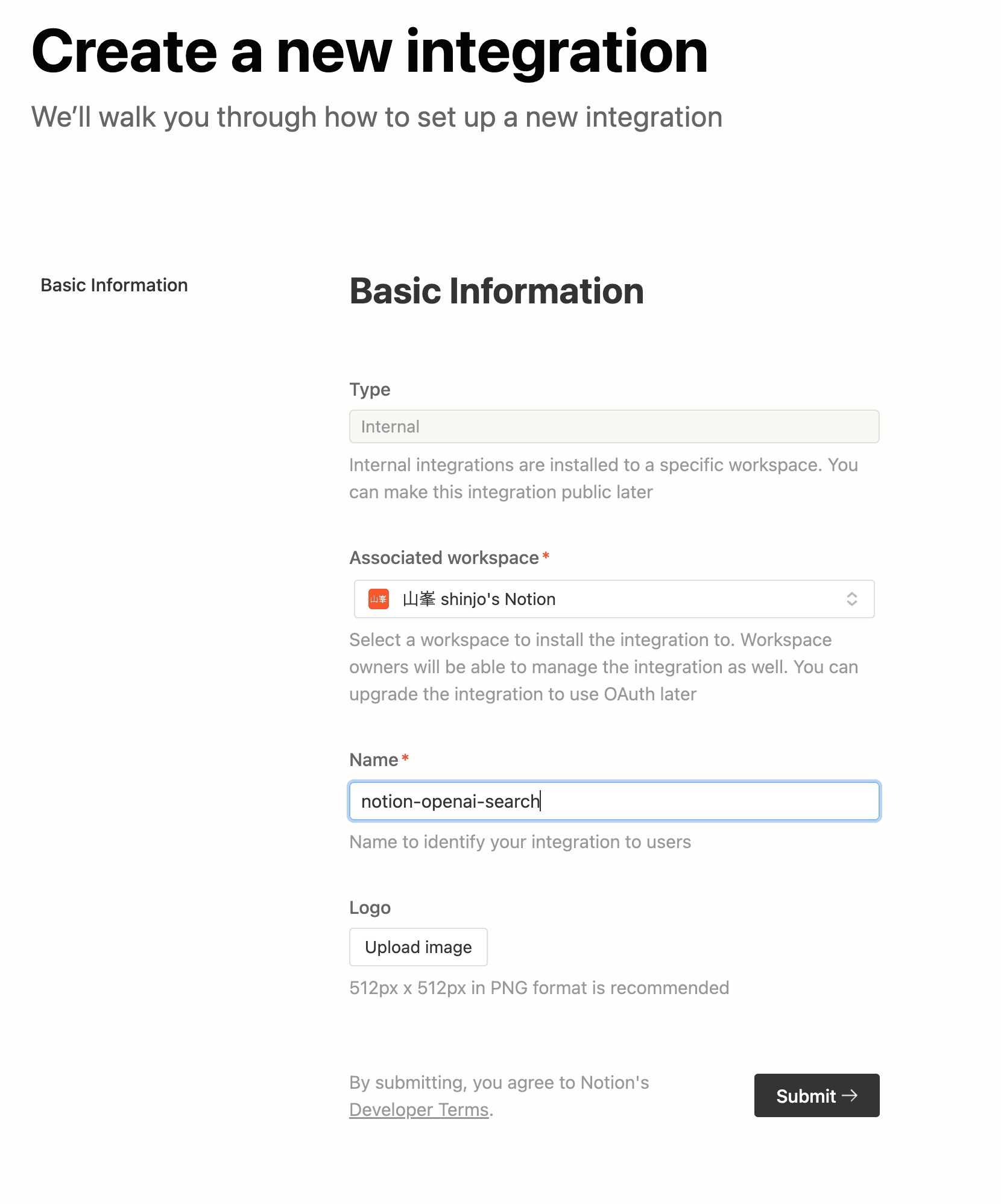
Notionにintegrationを作成する
https://www.notion.so/my-integrationsにアクセスして、インテグレーションを作りましょう。権限はRead contentがあれば十分です。Internal integrations SecretをNOTION_TOKENとして保存しましょう。
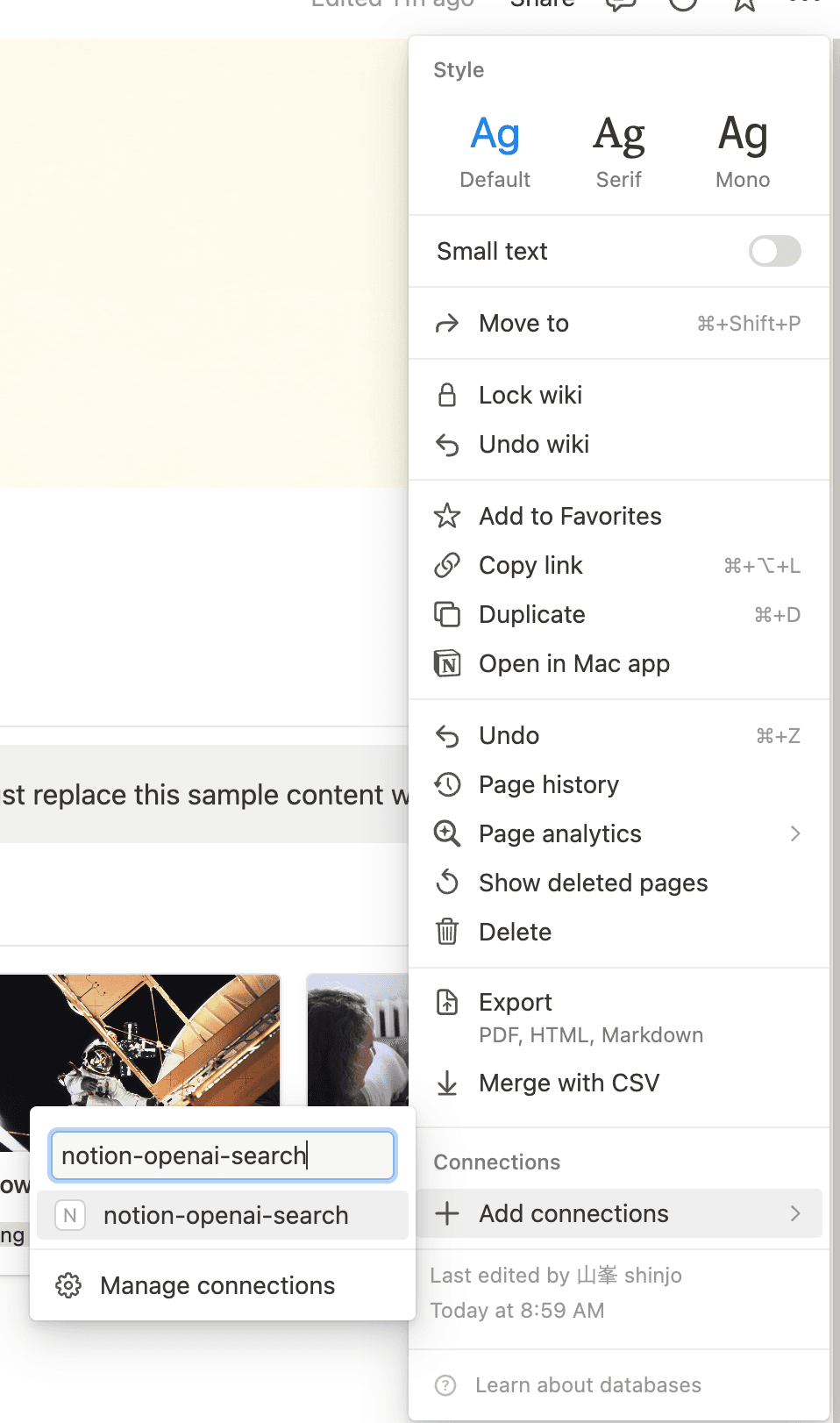
integrationをNotionのページと紐付ける
3点リードのメニューから+ Add connectionsを通して、作ったintegrationを紐付けましょう。子ページも全部紐付けてくれます。
NotionAPIでページを取得する
まずクライアントライブラリをインストールしましょう。
pnpm i @notionhq/client
NotionAPIでページを取得できるが、タイトルしか絞り込めないのにご注意ください。絞り込みたければ、Notion Databaseを使いましょう。
import { Client } from '@notionhq/client';
const notion = new Client({
auth: process.env.NOTION_TOKEN,
});
// get all pages id
const response = await notion.search({
filter: {
property: 'object',
value: 'page',
},
});
// get page by id
const page = await notion.pages.retrieve({
page_id: 'PAGE_ID',
});
console.log(page);
取得したページをMarkdownの文字列へ変換
notion-to-mdを使って、NotionのページをMarkdownの文字列へ変換しましょう。
pnpm i notion-to-md
実はnotion.pages.retrieveを利用してpageのobjectを取得する必要がなく、notion-to-mdを使えばいいです。
const response = await notion.search({
filter: {
property: 'object',
value: 'page',
},
});
// transform all markdowns to string
const pages = (
await Promise.all(
response.results
.map(async ({ id }) => {
const mdBlocks = await n2m.pageToMarkdown(id);
const mdString = n2m.toMarkdownString(mdBlocks);
if (!mdString.parent) return null;
return { id, contents: mdString.parent };
})
.filter(Boolean),
)
).filter(Boolean);
markdownStringに変換される時、parentがundefinedになることがあるのでご注意ください。if (!mdString.parent) return null;
Markdownの文字列をASTへ変換して、セクションごとで分割する
ASTの分析する部分が面倒なので、実装と説明を割愛してとりあえずsupabaseのオープンソースのコードをそのまま流用します。ASTに興味があれば、簡単なASTを解説しているGatsbyJSのコードブロックにコピーボタンを追加するをご覧ください。
OpenAIのEmbeddingsモデル(text-embedding-ada-002)を使って、セクションごとのベクトルを生成し、PostgreSQLのpgvectorに保存する
この部分もほぼsupabaseのコードを流用します。ただし、supabaseがドキュメントのMarkdownを分析しているので、parent_page_idとpathを持っています。Notionのページにはそういう情報を保持する必要がありません。なので、この2つのカラムを削除します。逆に、Notion IDを保存すれば、OpenAIの回答にベースのNotionページのURLを返すことができます。
nods_pageを下記のように作成しましょう。
create table "public"."nods_page" (
id bigserial primary key,
notion_page_id text not null unique,
checksum text,
meta jsonb,
type text,
source text
);
ベクトルを生成するembeddingのモデルは一番安いtext-embedding-ada-002を使います。お金に心配する必要のない会社であれば、もっと精度の高いモデルを使ってもいいでしょう。
const configuration = new Configuration({
apiKey: process.env.OPENAI_KEY,
});
const openai = new OpenAIApi(configuration);
const embeddingResponse = await openai.createEmbedding({
model: 'text-embedding-ada-002',
input,
});
if (embeddingResponse.status !== 200) {
throw new Error(inspect(embeddingResponse.data, false, 2));
}
const [responseData] = embeddingResponse.data.data;
// embeddingのベクトルをpgvectorに保存する
await supabaseClient
.from('nods_page_section')
.insert({
page_id: page.id,
slug,
heading,
content,
token_count: embeddingResponse.data.usage.total_tokens,
embedding: responseData.embedding,
})
.select()
.limit(1)
.single();
試してみる
すべての設定が終わりましたら、ローカルで試せるでしょう。
ベクトルの生成
pnpm embedding
エラーもとりあえず無視しましょう。
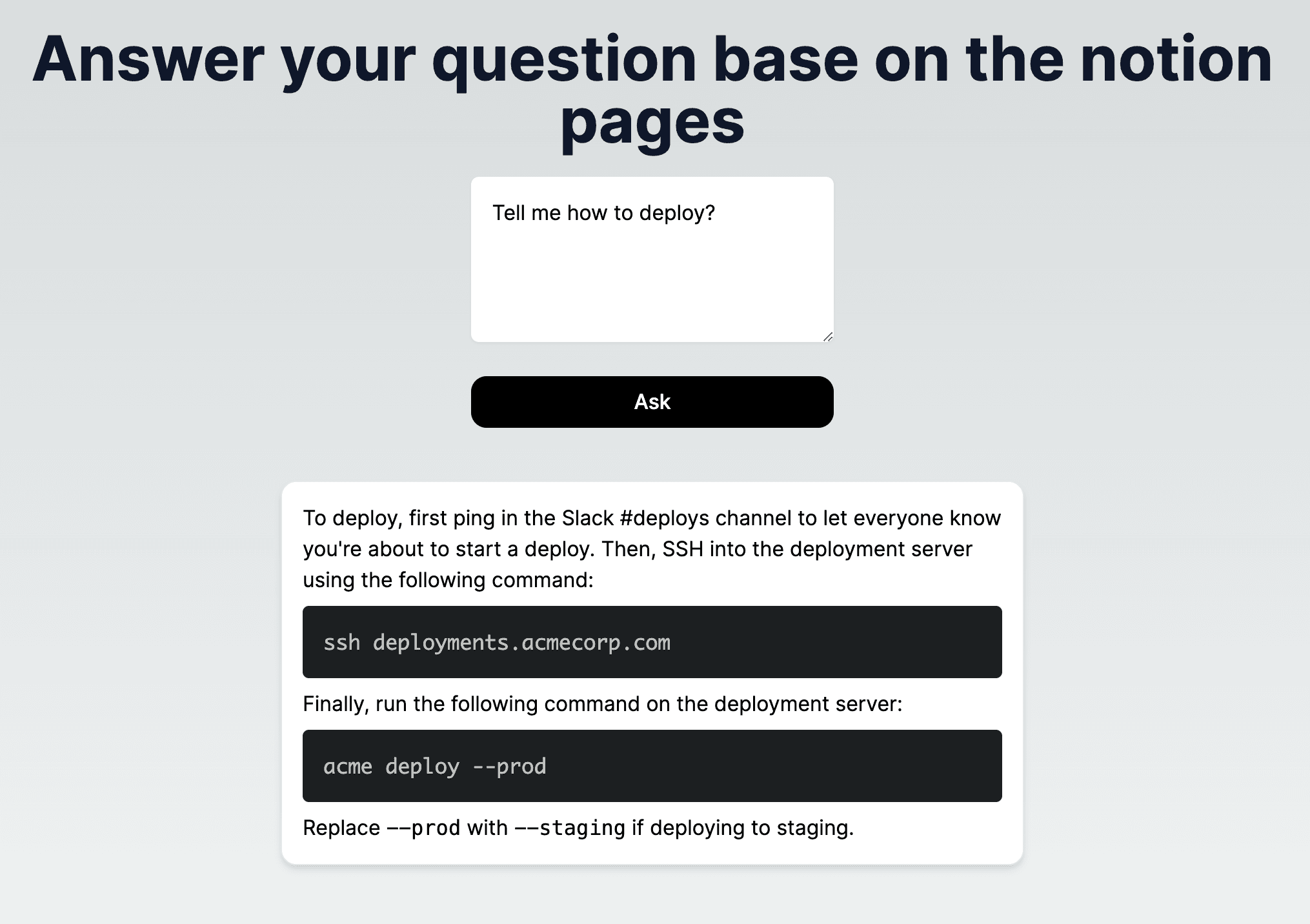
画面で検索する
pnpm dev
http://localhost:3000にアクセスして聞いてみたら。
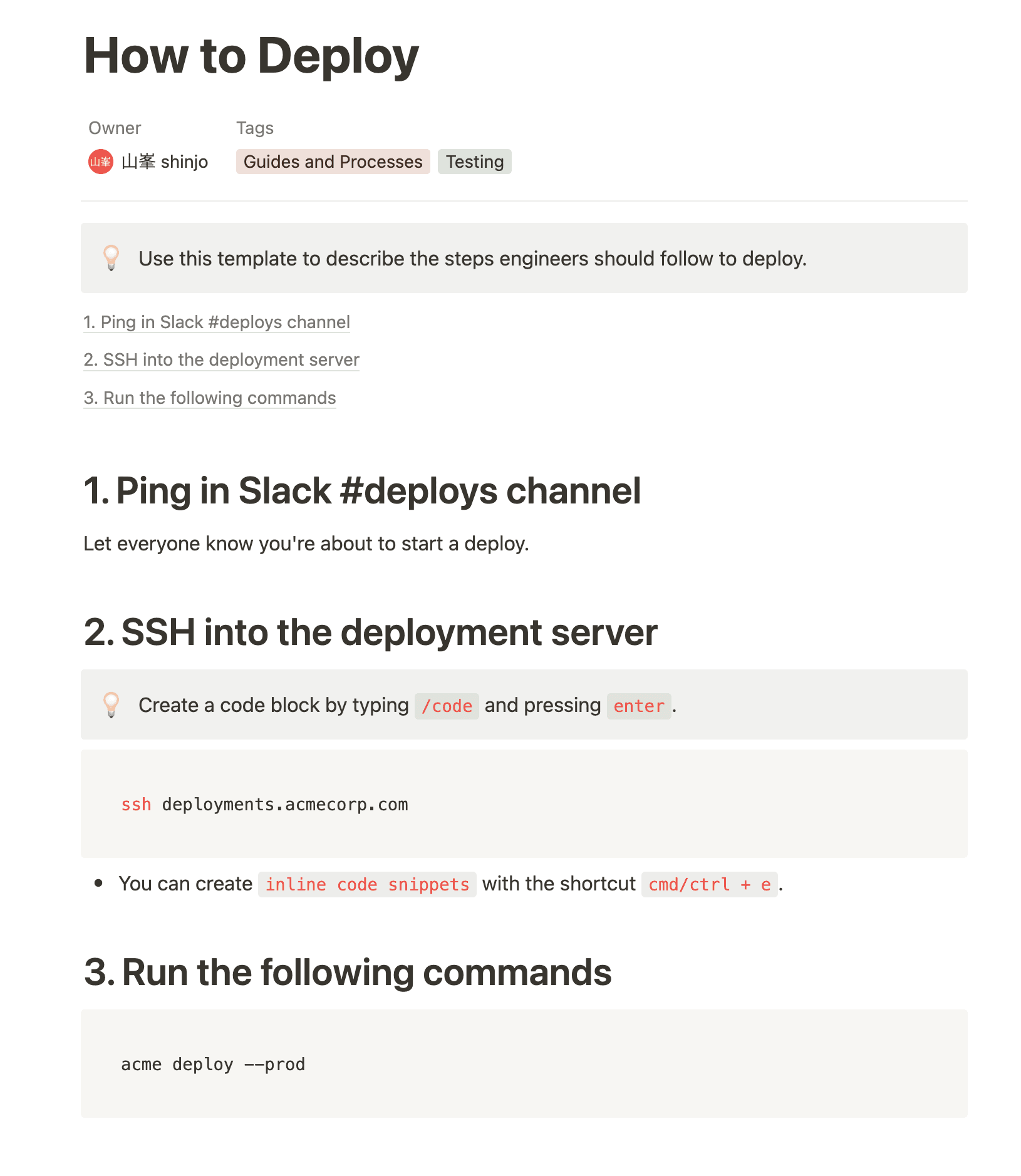
元のページはこれでしょう。関連する複数のセクションをまとめて答えてくれるので、かなり便利です。
まとめ
使っている技術がかなり多く、スクラッチ開発が困難な可能性があります。そのため、supabaseコミュニティのオープンソースをベースにして改造すれば、比較的早く開発できました。もちろん、supabase以外にもPineconeやVercelのPostgreSQLを使用することも問題ありません。また、ビジネス上の実用性を高めるために、Edge FunctionではなくLangChainを使用してSlackと連携することも考えられます。
すべてのNotionページをベクトルに変換するのは適切ではありません。代わりに必要なページに絞り込み、Notion Databaseを活用することをおすすめします。
さらに、現在はトークンの制限により、1つの質問に対して1回答しかできませんが、文字数を判断してコンテキストを加えることで、より賢く回答できるようになるでしょう。さまざまな可能性があります。興味があれば、ぜひ試してみてください。

Blog part of ThunderMiracle.com
コメントは表示領域に入ると読み込みます